
Challenge Description:
I found a suspicious program on my computer making HTTP requests to a web server. Please review the provided traffic capture and executable file for analysis. (Note: The flag has two parts.)
Step 1: Extract the provided zip folder
Extract the zip folder you were given. This folder contains a Windows binary and a PCAP file for analysis.
Step 2: Analyze the PCAP File
Tools Used: Network Miner, Wireshark
Open the provided PCAP file in Network Miner. You can also use Wireshark to manually inspect the captured traffic.
Step 3: Inspect the HTTP Response in Wireshark
In Wireshark, filter for http.response to locate the relevant HTTP responses.
You should see a stream of data containing random words, numbers, and symbols. These are likely important for obtaining the flag.
Step 4: Extracting Data from the HTTP Response
Upon closer inspection, it becomes clear that the program is likely concatenating the first letter of each word in the response to form a string. The string is likely base64 encoded.

Step 5: Write a Python Script to Extract the First Letter
Create a Python script that will extract the first letter of each word from the response data, keeping symbols and numbers intact.
def extract_first_letters(file_path):
result = ""
try:
# Open the file for reading
with open(file_path, 'r') as file:
content = file.read() # Read the entire content
# Split the content by spaces to get each word
words = content.split()
for word in words:
# If the word starts with an alphabetic letter, take its first character
if word[0].isalpha():
result += word[0]
else:
# Otherwise, keep the symbol or number as-is
result += word[0]
print("Extracted String:", result)
except FileNotFoundError:
print(f"Error: File '{file_path}' not found.")
except Exception as e:
print(f"An error occurred: {e}")
# Example usage
file_path = "yo.txt" # Change to the path of your text file
extract_first_letters(file_path)
Step 6: Run the Python Script
After running the script on the extracted text file, you'll get an output like the following:
python yo.py
Extracted String: IFZvbHVtZSBpbiBkcml2ZSBDIGhhcyBubyBsYWJlbC4NCiBWb2x1bWUgU2VyaWFsIE51bWJlciBpcyBBMDc5LUFERkINCg0KIERpcmVjdG9yeSBvZiBDOlxUZW1wDQoNCjA1LzA3LzIwMjQgIDA5OjIyIEFNICAgIDxESVI+ICAgICAgICAgIC4NCjA1LzA3LzIwMjQgIDA5OjIyIEFNICAgIDxESVI+ICAgICAgICAgIC4uDQowNS8wNy8yMDI0ICAwNzoyMyBBTSAgICAgICAgNjcsNTE1LDc0NCBzbXBob3N0LmV4ZQ0KICAgICAgICAgICAgICAgMSBGaWxlKHMpICAgICA2Nyw1MTUsNzQ0IGJ5dGVzDQogICAgICAgICAgICAgICAyIERpcihzKSAgMjksNjM4LDUyMCw4MzIgYnl0ZXMgZnJlZQ0KJ2g3N1BfczczNDE3aHlfcmV2U0hFTEx9JyANCg==
Step 7: Decode the Base64 String in CyberChef
Go to CyberChef ( https://gchq.github.io/CyberChef/) and paste the extracted string.
Use the Base64 Decode operation to decode the string.
You will receive the second part of the flag.

Step 8: Analyze the Executable Binary
Next, open the Windows binary in Detect It Easy to determine its origin and the framework it was compiled with.
The binary is identified as a .NET executable.

Step 9: Use dotPeek for Further Analysis
Open the .NET binary in dotPeek (or any other .NET decompiler) to analyze its functionality.
Look for any dictionaries or strings that could help identify what the binary is doing.
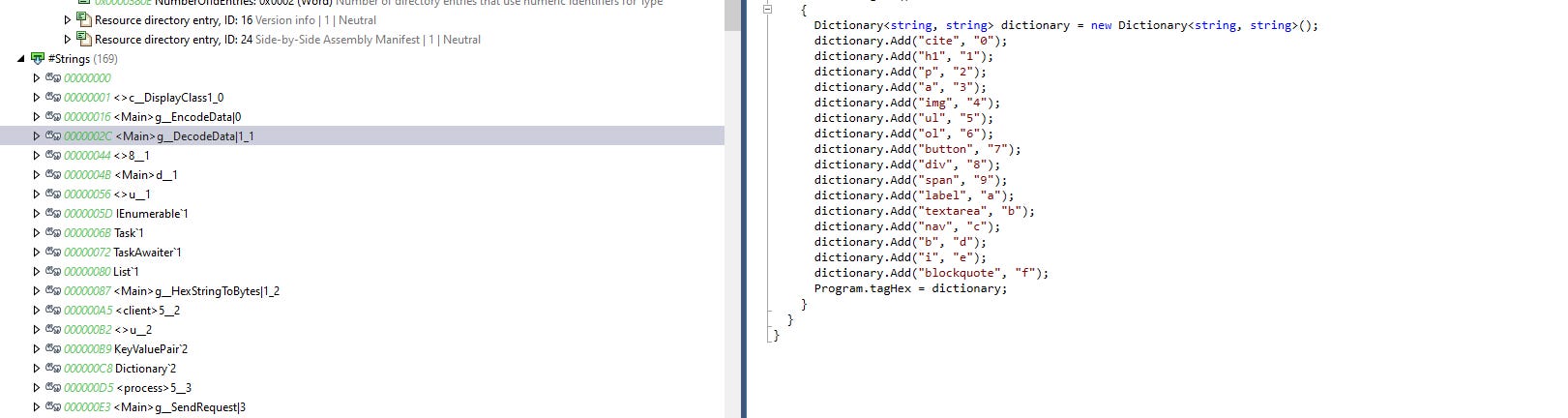
Step 10: Use the Information from dotPeek to Decode the HTML
The analysis reveals that the binary uses specific tags that map to hexadecimal values. These tags are crucial for decoding the HTML data found in the PCAP file.

Step 11: Write a Python Program to Decode the HTML
Write a Python script to decode the HTML content based on the tag-to-hex mapping you found in dotPeek.
import base64
import random
import re
# Tag to hex mapping (same as the original C# program)
tag_hex = {
"cite": "0", "h1": "1", "p": "2", "a": "3", "img": "4", "ul": "5", "ol": "6",
"button": "7", "div": "8", "span": "9", "label": "a", "textarea": "b", "nav": "c",
"b": "d", "i": "e", "blockquote": "f"
}
def decode_html(input_file):
# Read the HTML content from the file
with open(input_file, 'r') as f:
html_content = f.read()
# Function to decode the data from base64 string using tag_hex mapping
def decode_data(data):
# Find all the tags in the body content and replace them with the hex mapping
decoded_str = ""
# Match opening tags and replace them with their corresponding hex values
matches = re.findall(r'<(\w+)[\s>]', data)
for match in matches:
if match in tag_hex:
decoded_str += tag_hex[match]
# Print the hex string before converting to bytes
print("Hex String:", decoded_str)
# Try converting the hex string into bytes and decode it to ASCII
try:
decoded_bytes = bytes.fromhex(decoded_str)
decoded_ascii = decoded_bytes.decode('ascii')
return decoded_bytes, decoded_ascii
except ValueError as e:
# Handle the error gracefully if invalid hex is encountered
return f"Error decoding hex: {str(e)}", None
# Decode the HTML content using the decode_data function
decoded_bytes, decoded_html = decode_data(html_content)
return decoded_bytes, decoded_html
# Take the file path as input from the user
input_file = input("Please enter the path to the HTML file: ")
decoded_bytes, decoded_html = decode_html(input_file)
# Output the decoded bytes and ASCII
if decoded_html:
print("\nDecoded ASCII:")
print(decoded_html)
print("\nDecoded Bytes:")
print(decoded_bytes)
Step 12: Run the Python Decoder
Save the HTML content to a file and run it through the Python decoder.
This should give you the first part of the flag.

Conclusion
You should now have both parts of the flag after following these steps.
Second Part of the Flag: Extracted via base64 decoding.
First Part of the Flag: Decoded from HTML using tag-to-hex mapping.
Congratulations on completing the "Fishy HTTP" challenge!